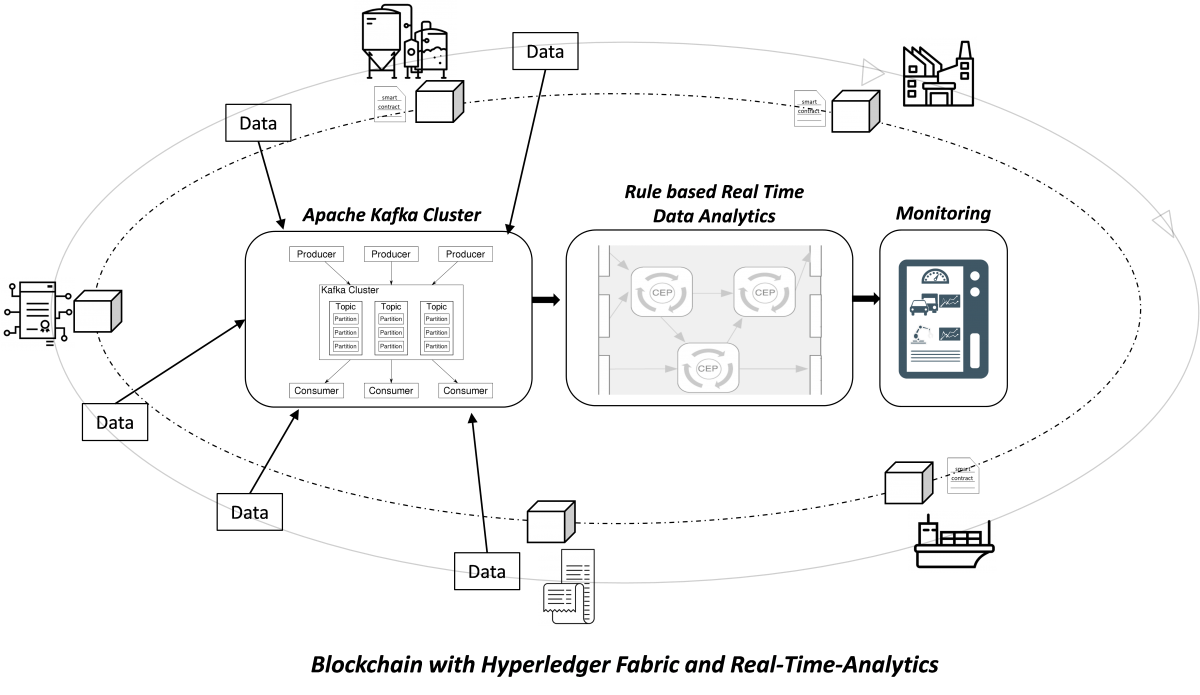
Im Zuge der iterativen Anforderungsanalyse zeigt sich, eine Tendenz hinzu der Hyperledger-Fabric-Implementierung. Daher wird für die Architektur der Echtzeitdatenverarbeitung dies als Grundlage genutzt. Da der Datenaustausch der Hyperledger Fabric mittels dem Publish/Subscribe-System Apache Kafka umgesetzt wird, werden hierbei erhebliche Synergieeffekte mit verschiedenen Stream-Processing-Architekturen erzeugt. Hierdurch ergibt sich eine Stream-First-Architektur. Diese Stream-First-Architektur muss zum einen den Nachrichtentransport, zum anderen eine Datenstromverarbeitung ermöglichen (Friedman und Tzoumas 2016). Innerhalb des Nachrichtentransports muss die Möglichkeit bestehen Datensätze permanent speichern zu können, um bei Fehlern in Applikationen auf bereits verarbeitete Daten erneut zugreifen zu können. Des Weiteren müssen, falls die Datenverarbeitung temporär nicht verfügbar ist, alle in diesem Zeitraum entstanden Datensätze für die Datenverarbeitung gespeichert werden, um eine spätere Verarbeitung aller Datensätze garantieren zu können (Friedman und Tzoumas 2016). Apache Kafka ist in der Lage diese Anforderungen zu erfüllen (Shapira 2017). Apache Flink sowie EsperTech CEP eignen sich in diesem Szenario als Datenstromverarbeitung auf Basis eines Regel-basierenden Ansatzes (Complex-Event-Processing) durch die hohe Skalierbarkeit, der Zuverlässigkeit und den vielen Datenverarbeitungsmöglichkeiten (Friedmann 2016; EsperTech Inc. 2019).
Erste Ergebnisse anhand verschiedener Testdatensätze zeigen, dass bei einer hohen Menge an Daten (Stichwort Big Data) diese Stream-First-Architecture eine Überwachung und Steuerung von Wertschöpfungsnetzwerken in Echtzeit ermöglichen kann.
Ansprechpartner: Lukas-Valentin Herm (Juniorprofessur für Information Management, Universität Würzburg)
Literatur:
Etzion, O.; Niblett, P. (2010): Event processing in action, Manning, Greenwich, Conn.
Eugster, P. T.; Felber, P. A.; Guerraoui, R.; Kermarrec, A.-M. (2003): The many faces of
publish/subscribe. In: ACM Computing Surveys 35 (2), 114–131.
EsperTech Inc. (2019): Esper Documentation. In: http://www.espertech.com/esper/esper-documentation, zugegriffen am 27.06.2019.
Friedman, E.; Tzoumas, K. (2016): Introduction to Apache Flink. Stream processing for real
time and beyond. First edition, O’Reilly, Beijing, Boston, Farnham, Sebastopol, Tokyo.
Shapira, G.; Palino, T.; Narkhede, N. (2017): Kafka: The Definitive Guide. Real-Time Data and
Stream Processing at Scale, O’Reilly Media, Inc.